Orginal Article
Qing Liu, Kebiao Mao, Ying Ma, Xuelan Tan, Jiaqi Han, Lingping Li, Lang Xia
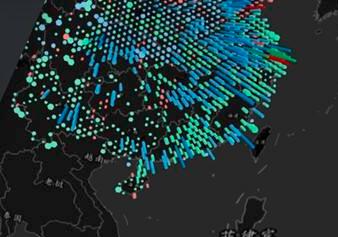
This article researched into the pig’s circulation in China by using data visualization and combined analysis of the current status of pig’s circulation and the Chinese urban agglomeration. At the end of the study, the results showed the spatial distribution pattern of pigs in China based on the status quo of the development of urban agglomeration, and provided the basis for policy formulation for the relevant agricultural sector. In this article, Beijing, Tianjin, Shanghai, Chongqing, Heilongjiang, Jilin, Liaoning, Shandong, Hebei, Henan, Hubei, Hunan, Anhui, Jiangsu, Zhejiang, Sichuan, Yunnan, Guangdong, Guangxi and municipalities were chosen as the research object. Firstly, statistical data on pigs was integrated with GIS data, remote sensing data and network data to result in an integrated multi-source data. When big data technology and GIS was used to visualize this integrated multi-source data we can get the status quo of pig’s circulation in 19 provinces and municipalities. The visualization process was based on the New national urbanization plan (2014-2020) and the results of previous studies for dividing China into urban agglomeration. The results of the study was due to the combined analysis of the status quo of the pig’s circulation and the visualization results of the urban agglomeration in china. The study summed up the current situation of the pigs circulation of the city group to get the spatial distribution pattern of pigs based on the development of urban agglomeration in China. Finally, the problems of the distribution pattern of pigs in China was analyzed to give the corresponding solutions. According to the analysis of the spatial distribution of pigs, the research object was divided into 4 categories: The first category showed that the region needs to be supplied with a large number of pigs, including Beijing, Shanghai, Jiangsu, Zhejiang, Guangdong; The second category showed that, the region have both pigs inflow and outflow, including the three northeastern provinces, Henan, Shandong, Hubei, Hunan, Sichuan; The third category showed that, live pigs move out of the region including Hebei, Anhui, Yunnan, Guangxi; The fourth category is Chongqing, there is not a lot of pigs inflow and outflow. Beijing, Tianjin city group, the Yellow River Delta city group and the Zhujiang River Delta city group is the most important pork consumption areas, 69.6% of the pigs flow is related to the three groups. The main pigs production areas are concentrated in the middle, the east, the southwest and the northeast of China, and the east and southeast coastal areas are the main pigs consumption—it can be summarized as ‘pigs of the west supply in the east, pigs of the north supply in the south’. The eastern coastal areas are the most important part of the pig’s circulation system in China, the production and consumption of the pigs in the eastern coastal areas is the key factor for the change of the pig’s circulation pattern in China.