
Remote Sensing for Natural Resources >
Semantic segmentation of high-resolution remote sensing images based on context- and class-aware feature fusion
Received date: 2023-10-14
Revised date: 2024-03-06
Online published: 2026-06-03
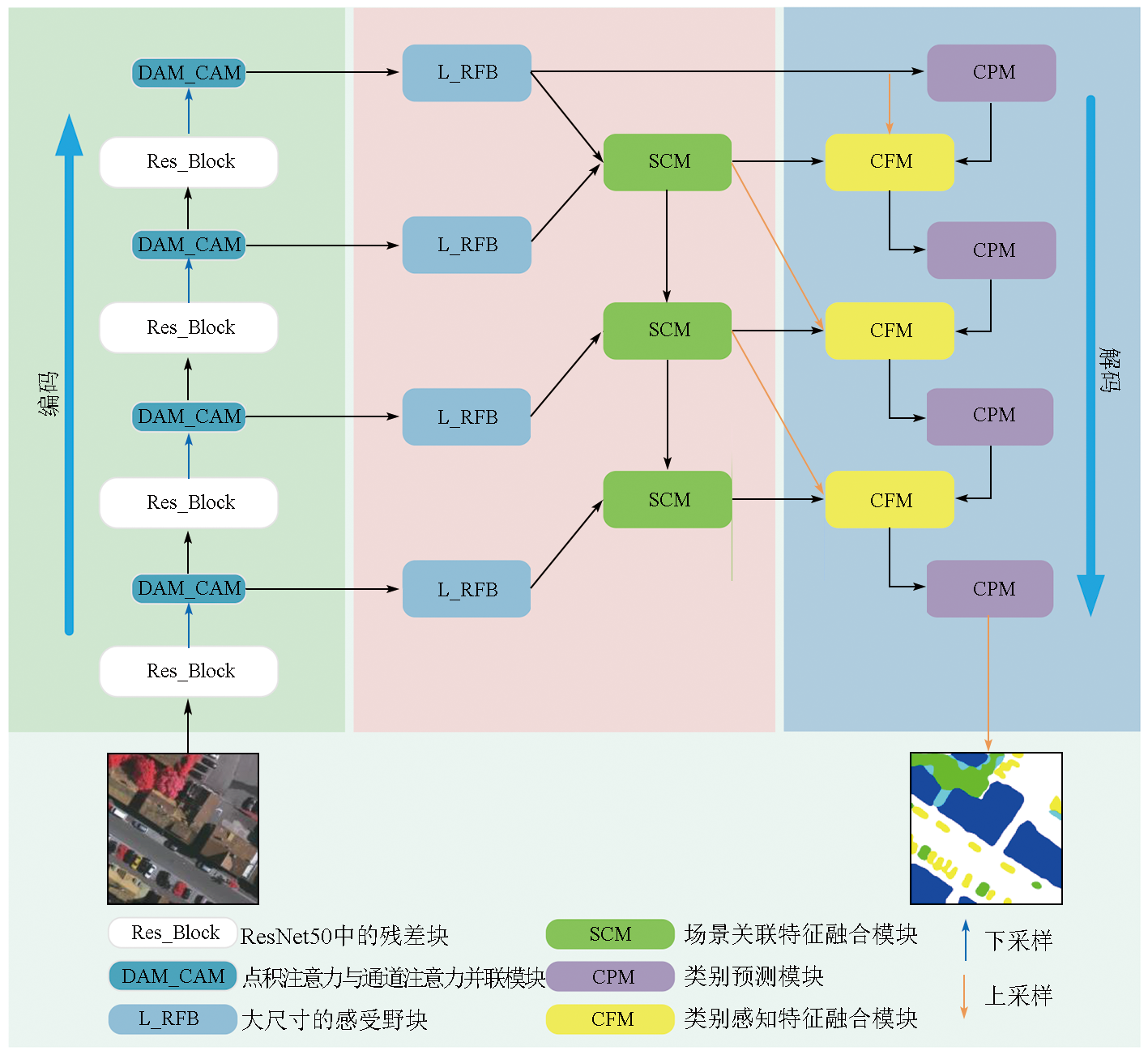
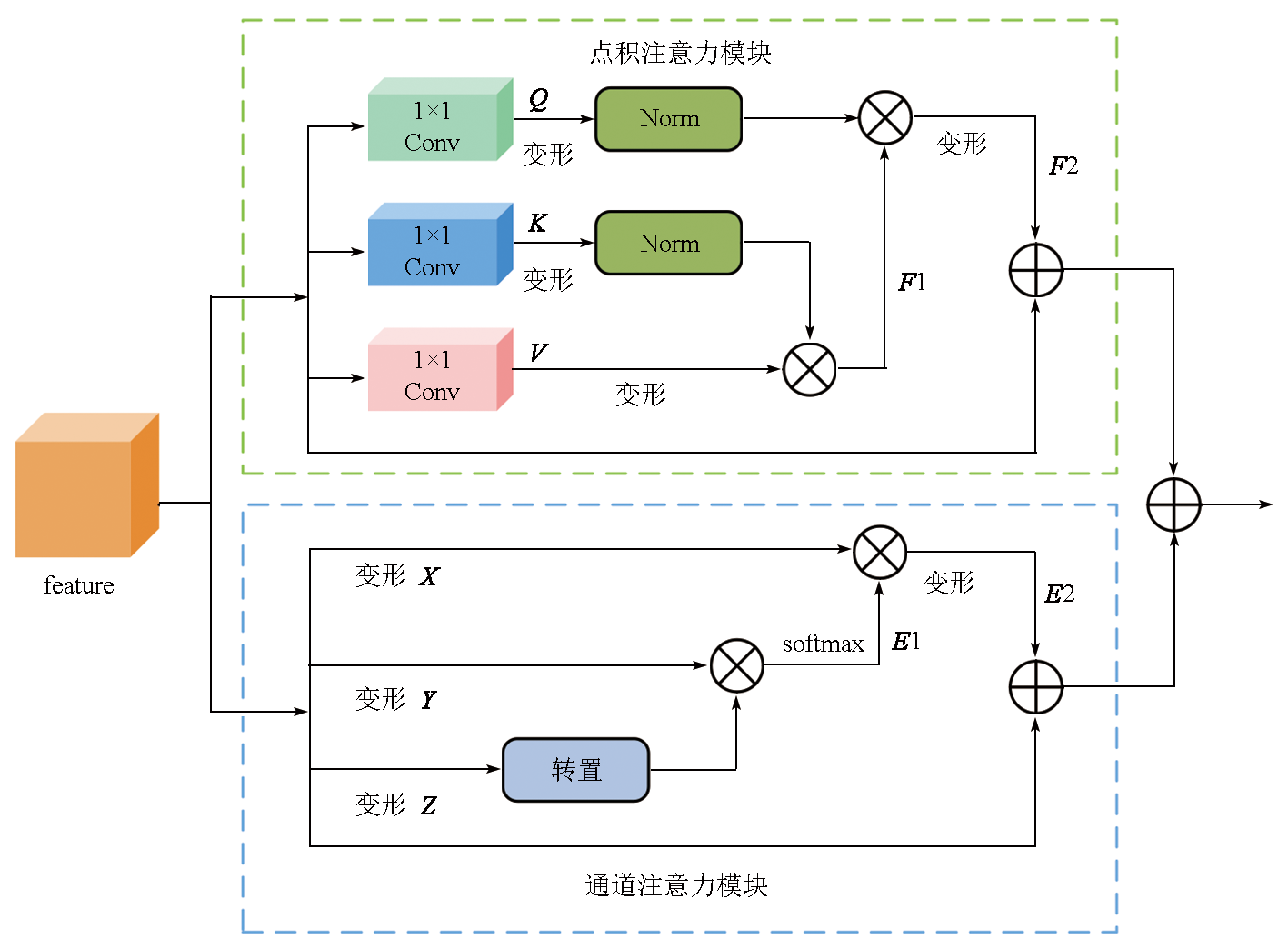
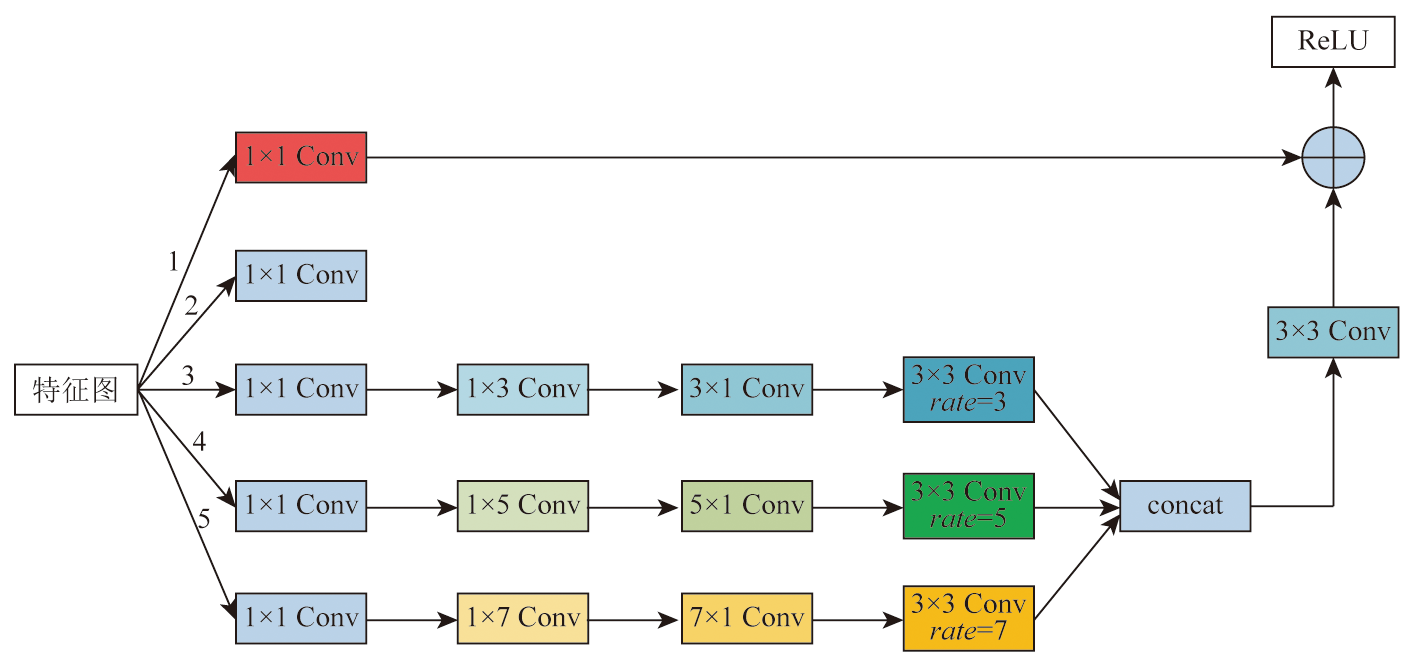
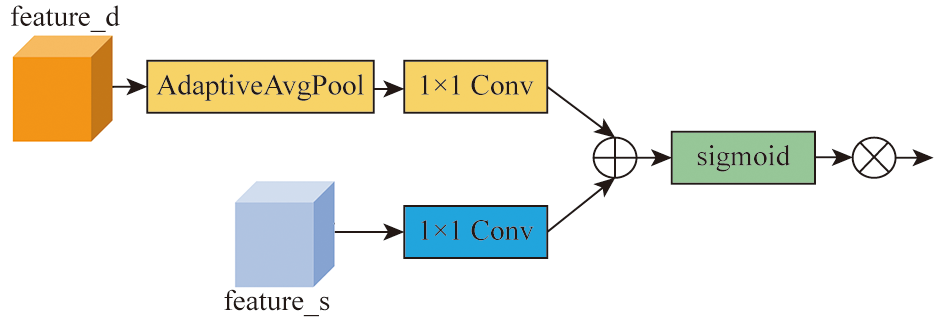
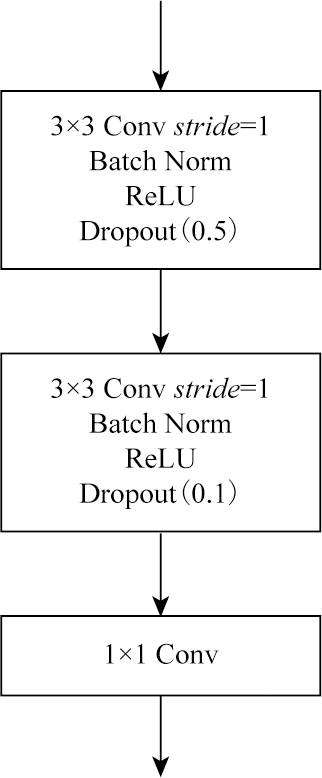
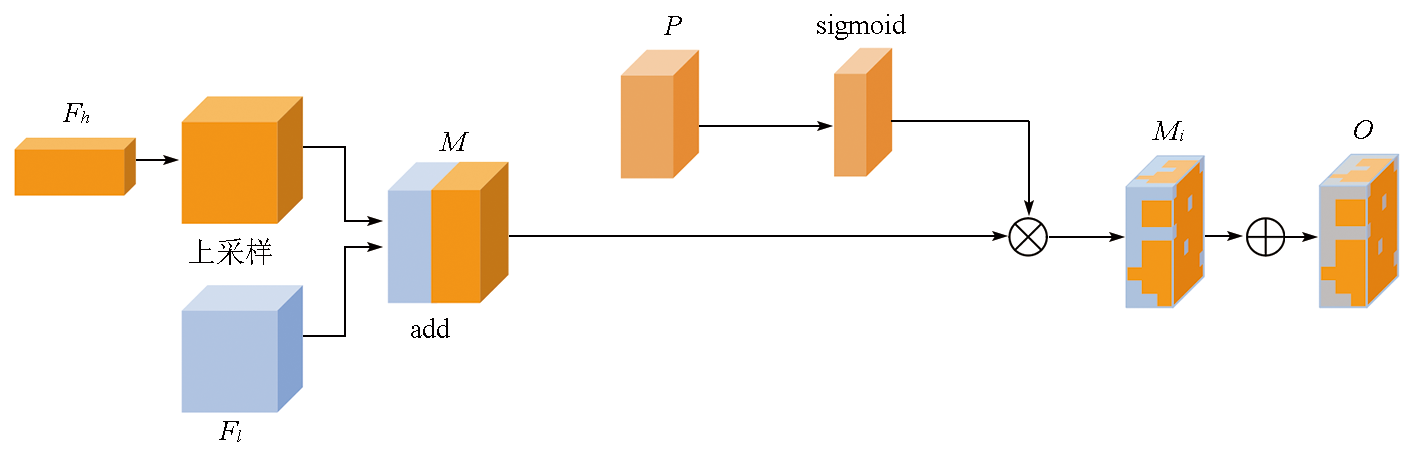
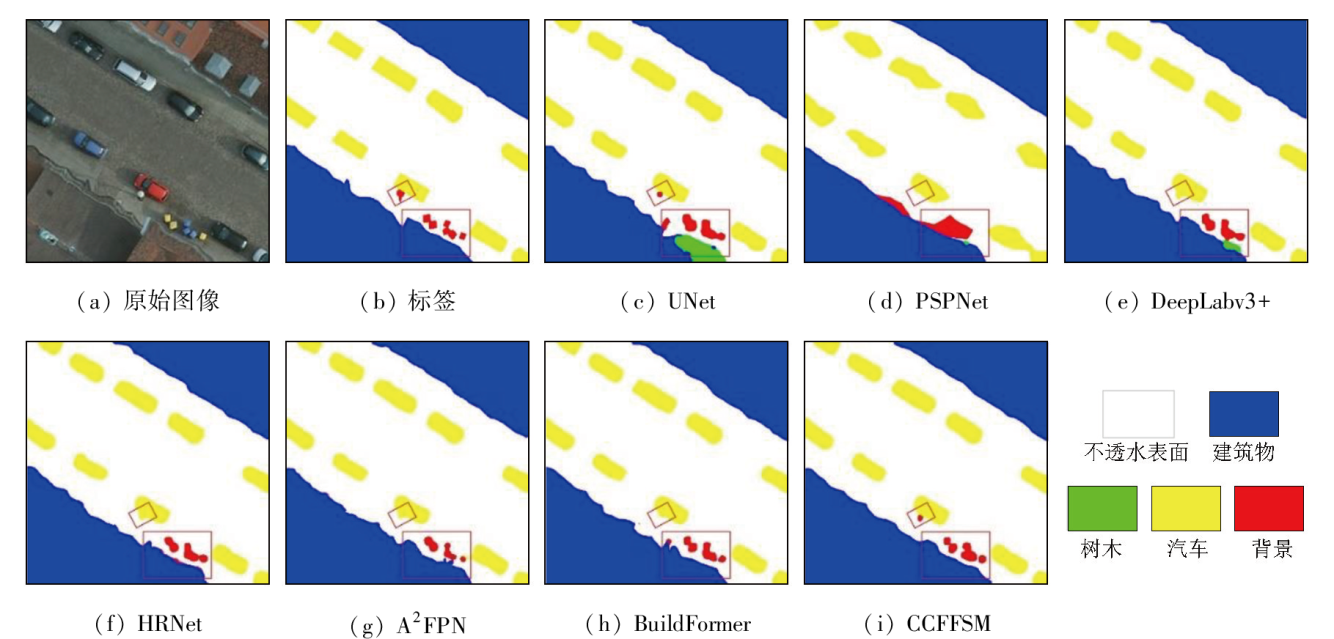
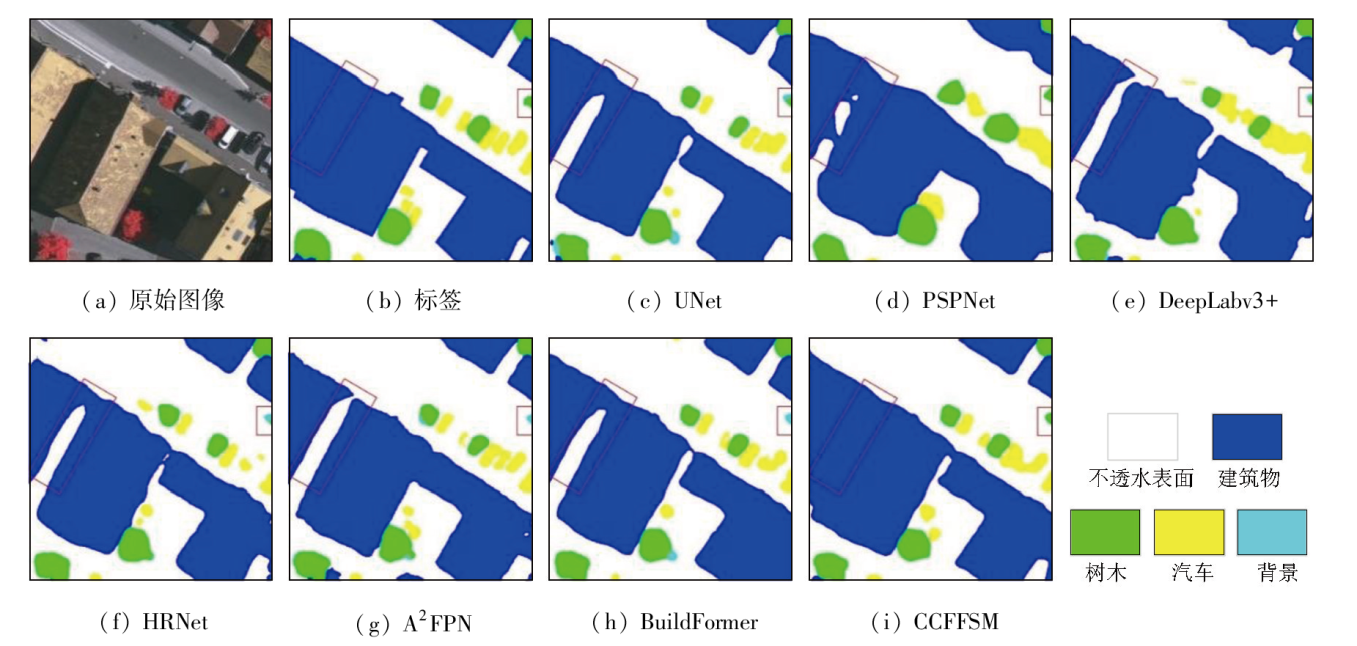
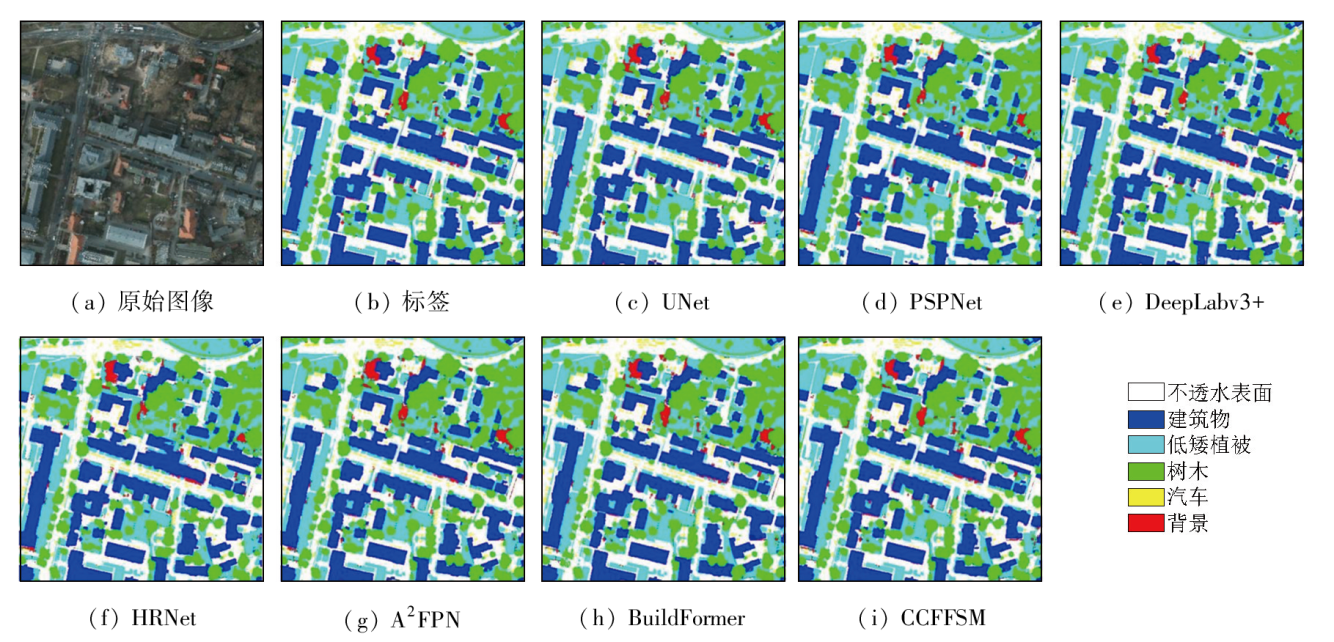
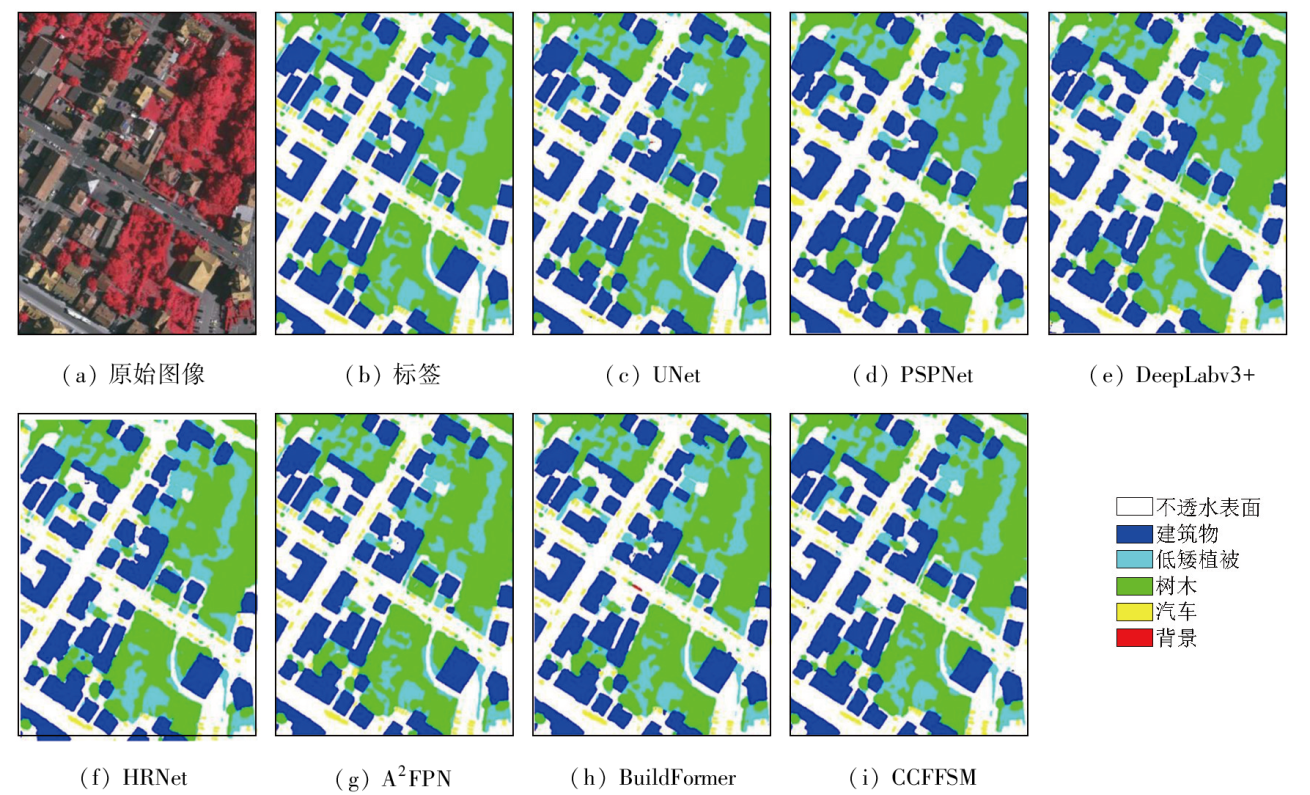
To address the accuracy reduction in the semantic segmentation of remote sensing images due to insufficient extraction of contextual dependencies and loss of spatial details, this study proposed a semantic segmentation method based on context- and class-aware feature fusion. With ResNet-50 as the backbone network for feature extraction, the proposed method incorporates the attention module during downsampling to enhance feature representation and contextual dependency extraction. It constructs a large receptive field block on skip connections to extract rich multiscale contextual information, thereby mitigating the impacts of scale variations between targets. Furthermore, it connects a scene feature association and fusion module in parallel behind the block to guide local feature fusion based on global features. Finally, it constructs a class prediction module and a class-aware feature fusion module in the decoder part to accurately fuse the low-level advanced semantic information with high-level detailed information. The proposed method was validated on the Potsdam and Vaihingen datasets and compared with six commonly used methods, including DeepLabv3+ and BuildFormer, to verify its effectiveness. Experimental results demonstrate that the proposed method outperformed other methods in terms of recall, F1-score, and accuracy. Particularly, it yielded intersection over union (IoU) values of 90.44% and 86.74% for building segmentation, achieving improvements of 1.55% and 2.41%, respectively, compared to suboptimal networks DeepLabv3+ and A2FPN.
HE Xiaojun , LUO Jie . Semantic segmentation of high-resolution remote sensing images based on context- and class-aware feature fusion[J]. Remote Sensing for Natural Resources, 2025 , 37(2) : 1 -10 . DOI: 10.6046/zrzyyg.2023312
表1 Potsdam和Vaihingen数据集Tab.1 Potsdam and Vaihingen datasets |
| 数据集 | Potsdam数据集 | Vaihingen数据集 |
|---|---|---|
| 数据来源 | ISPRS | ISPRS |
| 波段 | IRRGB DSM | IRRG DSM |
| 使用波段 | R,G,B | R,G,B |
| 地面采样距离/cm | 5 | 9 |
| 样本大小/像素 | 6 000×6 000 | 1 996×1 995~3 816×2 550 |
| 样本数量/个 | 38 | 33 |
表2 在Potsdam数据集上的实验结果Tab.2 Experimental results on the Potsdam dataset (%) |
| 模型 | Precision | Recall | F1-score | Accuracy |
|---|---|---|---|---|
| UNet | 87.43 | 82.77 | 84.50 | 87.36 |
| PSPNet | 84.34 | 81.46 | 82.53 | 86.38 |
| DeepLabv3+ | 87.09 | 83.65 | 84.92 | 87.67 |
| HRNet | 85.11 | 80.88 | 82.25 | 85.94 |
| A2FPN | 86.71 | 83.18 | 84.52 | 87.42 |
| BuildFormer | 86.65 | 83.48 | 84.71 | 87.52 |
| CCFFSM | 88.33 | 84.47 | 85.83 | 88.54 |
表3 在Vaihingen数据集上的实验结果Tab.3 Experimental results on the Vaihingen dataset (%) |
| 模型 | Precision | Recall | F1-score | Accuracy |
|---|---|---|---|---|
| UNet | 86.11 | 76.21 | 78.55 | 87.39 |
| PSPNet | 77.21 | 72.08 | 73.84 | 83.74 |
| DeepLabv3+ | 83.80 | 74.14 | 75.60 | 86.15 |
| HRNet | 84.09 | 75.61 | 78.23 | 86.98 |
| A2FPN | 85.35 | 78.45 | 80.20 | 88.10 |
| BuildFormer | 85.57 | 75.94 | 78.29 | 87.86 |
| CCFFSM | 86.74 | 78.94 | 81.24 | 88.82 |
表4 Potsdam数据集IoU得分Tab.4 IoU scores on the Potsdam (%) |
| 模型 | IoU | mIoU | ||||
|---|---|---|---|---|---|---|
| 不透水 表面 | 建筑物 | 低矮 植被 | 树木 | 汽车 | ||
| UNet | 80.18 | 88.59 | 71.32 | 72.26 | 79.67 | 78.40 |
| PSPNet | 78.47 | 87.79 | 69.34 | 72.46 | 64.17 | 74.44 |
| DeepLabv3+ | 81.19 | 89.06 | 71.11 | 72.79 | 80.94 | 79.01 |
| HRNet | 78.13 | 85.98 | 70.26 | 69.95 | 75.92 | 76.04 |
| A2FPN | 80.91 | 88.48 | 70.69 | 72.59 | 78.44 | 78.22 |
| BuildFormer | 80.96 | 88.65 | 71.93 | 71.89 | 80.43 | 78.77 |
| CCFFSM | 82.32 | 90.44 | 72.54 | 75.02 | 80.82 | 80.23 |
表5 Vaihingen数据集IoU得分Tab.5 IoU scores on the Vaihingen dataset (%) |
| 模型 | IoU | mIoU | ||||
|---|---|---|---|---|---|---|
| 不透水 表面 | 建筑物 | 低矮 植被 | 树木 | 汽车 | ||
| UNet | 78.74 | 83.24 | 64.12 | 73.33 | 53.24 | 70.53 |
| PSPNet | 71.55 | 77.94 | 58.38 | 67.36 | 28.66 | 60.77 |
| DeepLabv3+ | 76.18 | 81.13 | 62.24 | 71.88 | 43.58 | 67.00 |
| HRNet | 77.47 | 81.16 | 64.68 | 73.08 | 46.11 | 68.50 |
| A2FPN | 79.07 | 84.70 | 65.73 | 74.42 | 56.70 | 72.12 |
| BuildFormer | 79.17 | 83.68 | 65.84 | 73.90 | 51.04 | 70.72 |
| CCFFSM | 79.70 | 86.74 | 68.31 | 75.54 | 53.44 | 72.75 |
表6 CCFFSM方法消融实验结果Tab.6 Ablation experiment results of CCFFSM method (%) |
| 模块 | F1-score | mIoU |
|---|---|---|
| L_RFB+SCM+CPM+CFM | 79.58 | 71.14 |
| DAM_CAM+SCM+CPM+CFM | 80.83 | 71.85 |
| DAM_CAM+L_RFB+CPM+CFM | 80.16 | 72.51 |
| DAM_CAM+L_RFB+SCM+CFM | 80.74 | 71.62 |
| DAM_CAM+L_RFB+SCM+CPM | 81.45 | 65.43 |
| DAM_CAM+L_RFB+SCM+CPM+CFM | 81.24 | 72.75 |
| [1] |
刘钊, 赵桐, 廖斐凡, 等. 基于语义分割网络的高分遥感影像城市建成区提取方法研究与对比分析[J]. 国土资源遥感, 2021, 33(1):45-53.doi:10.6046/gtzyyg.2020162.
|
| [2] |
|
| [3] |
|
| [4] |
于航, 安娜, 汪洁, 等. 黔西南采煤塌陷区高分遥感动态监测——以六盘水市煤矿采空塌陷区为例[J]. 自然资源遥感, 2023, 35(3):310-318.doi:10.6046/zrzyyg.2022170.
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
赫晓慧, 陈明扬, 李盼乐, 等. 结合DCNN与短距条件随机场的遥感影像道路提取[J]. 武汉大学学报(信息科学版), 2024, 49(3):333-342.
|
| [9] |
|
| [10] |
龙丽红, 朱宇霆, 闫敬文, 等. 新型语义分割D-UNet的建筑物提取[J]. 遥感学报, 2023, 27(11):2593-2602.
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
刘尚旺, 崔智勇, 李道义. 基于Unet网络多任务学习的遥感图像建筑地物语义分割[J]. 国土资源遥感, 2020, 32(4):74-83.doi:10.6046/gtzyyg.2020.04.11.
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
张印辉, 张枫, 何自芬, 等. 注意力引导与多特征融合的遥感影像分割[J]. 光学学报, 2023, 43(24):3788/AOS230631.
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}