
Remote Sensing for Natural Resources >
A method for information extraction of buildings from remote sensing images based on hybrid attention mechanism and Deeplabv3+
Received date: 2023-09-22
Revised date: 2024-01-26
Online published: 2026-06-03
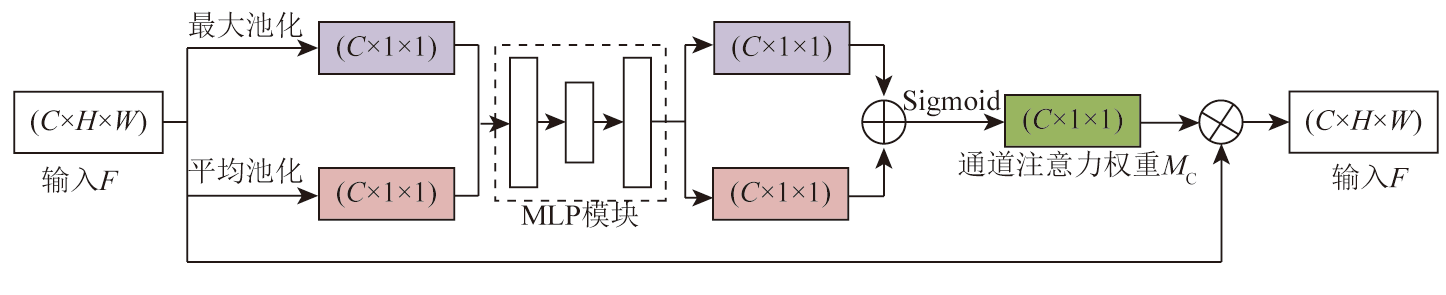
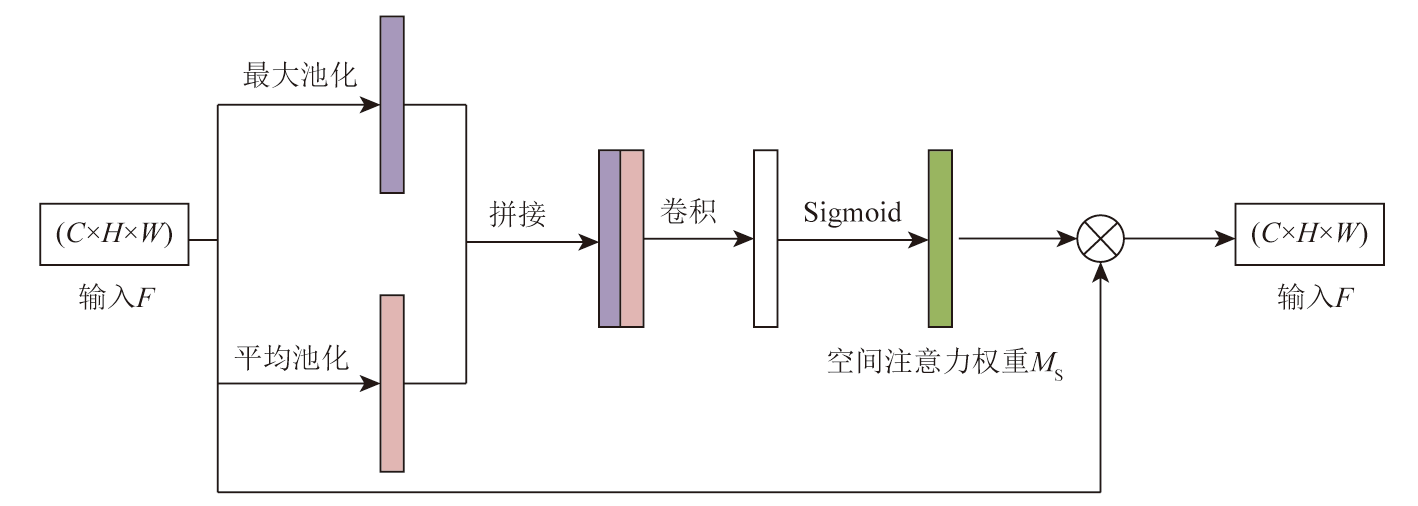
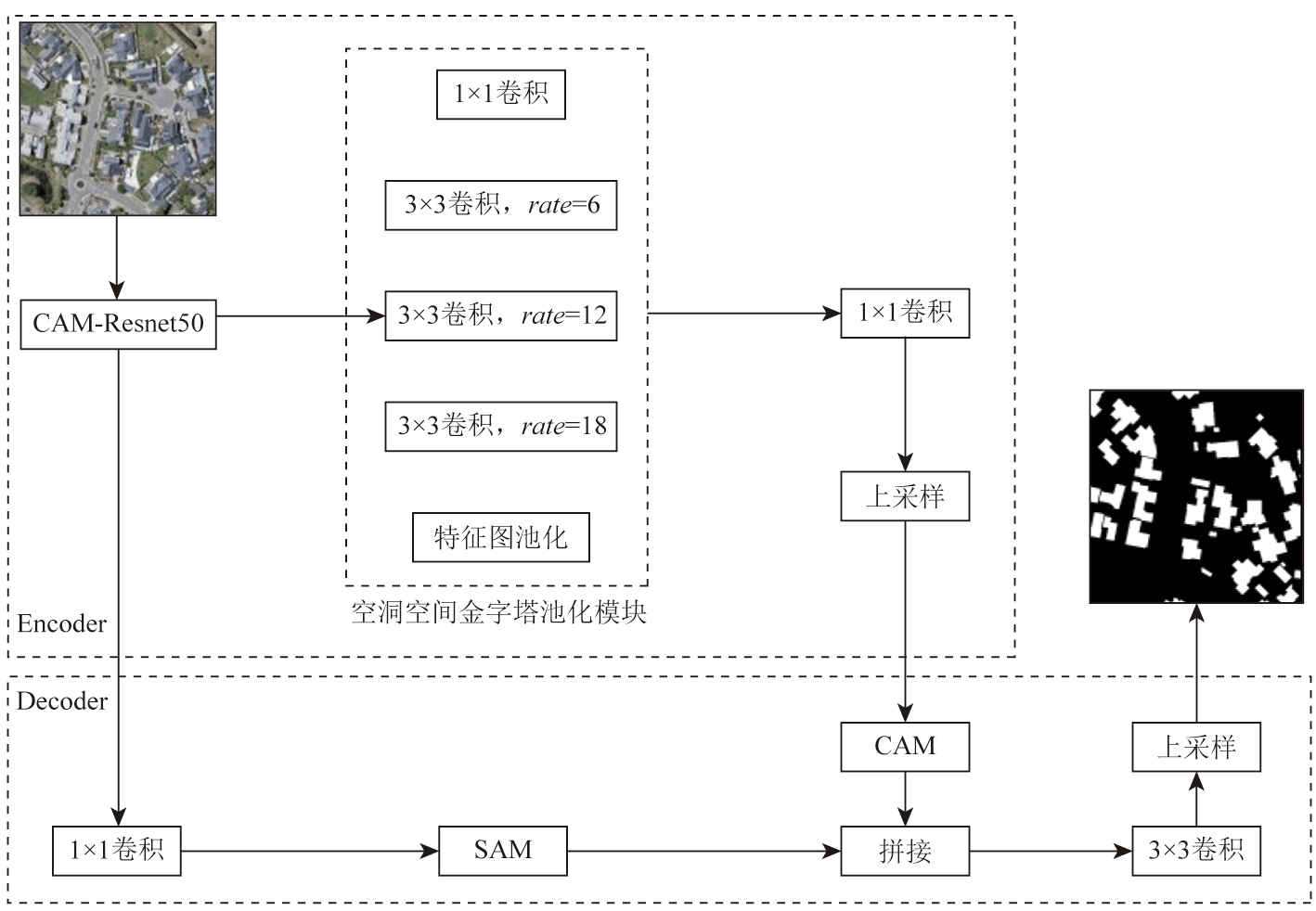
Extracting information about buildings from a large and complex set of remote sensing images has always been a hot research topic in the intelligent applications of remote sensing. To address issues such as inaccurate information extraction of buildings and the tendency to ignore small buildings within a complex environment in remote sensing images, this study proposed the SC-deep network-a semantic segmentation algorithm for remote sensing images based on a hybrid attention mechanism and Deeplabv3+. Utilizing an encoder-decoder structure, this network employs a backbone residual attention network to extract deep- and shallow-layer features. Meanwhile, this network aggregates the spatial and channel information weights in remote sensing images using a dilated space pyramid pool module and a channel-space attention module. These allow for effectively utilizing the multi-scale information of building structures in remote sensing images, thereby reducing the loss of image details during training. The experimental results indicate that the proposed method outperforms other mainstream segmentation networks on the Aerial imagery dataset. Overall, this method can effectively identify and extract the edges of complex buildings and small structures, exhibiting superior building extraction performance.
LIU Chenchen , GE Xiaosan , WU Yongbin , YU Haikun , ZHANG Beibei . A method for information extraction of buildings from remote sensing images based on hybrid attention mechanism and Deeplabv3+[J]. Remote Sensing for Natural Resources, 2025 , 37(1) : 31 -37 . DOI: 10.6046/zrzyyg.2023295
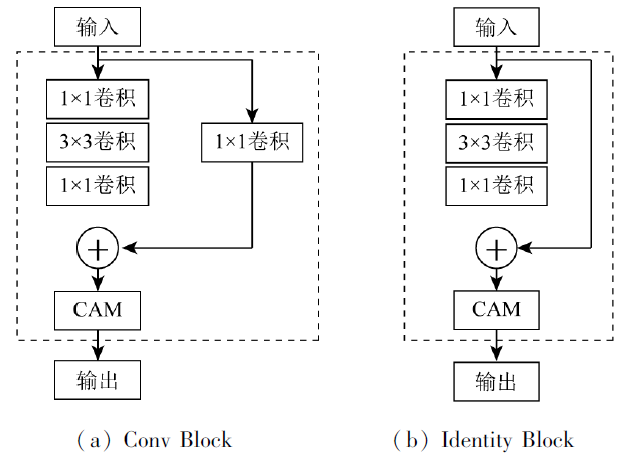
表1 CAM-Resnet50网络结构Tab.1 CAM-Resnet50 network structure |
| 层级名称 | 输入尺寸 | 操作模块 | 重复 次数 | 输出 通道数 |
|---|---|---|---|---|
| Conv1 | 2242×3 | 7×7卷积 | 1 | 128 |
| Conv2_x | 1122×64 | Conv Block | 1 | 256 |
| Identity Block | 2 | |||
| Conv3_x | 562×256 | Conv Block | 1 | 512 |
| Identity Block | 3 | |||
| Conv4_x | 282×512 | Conv Block | 1 | 1 024 |
| Identity Block | 5 | |||
| Conv5_x | 142×1 024 | Conv Block | 1 | 2 048 |
| Identity Block | 2 | |||
| Conv6 | 72×2 048 | 1×1卷积 | 1 | 2 048 |
表2 实验环境配置Tab.2 Experiment environment configuration |
| 实验环境 | 配置参数 |
|---|---|
| CPU | Intel(R) Xeon(R) Gold 6330 |
| 内存/GB | 80 |
| GPU | RTX 3090 |
| 显存/GB | 24 |
| CUDA | CUDA11.3 |
| 学习框架 | Pytorch1.10.0 |
| 编程语言 | Python3.8 |
表3 主干网络消融实验结果Tab.3 Results of backbone network ablation experiments (%) |
| 主干网络 | IoU | Precision | Recall | F1-score |
|---|---|---|---|---|
| Xception | 84.48 | 93.20 | 90.03 | 92.59 |
| mobilenetv2 | 83.94 | 91.33 | 91.21 | 91.27 |
| vit | 72.58 | 88.65 | 80.01 | 84.11 |
| CAM-Resnet50 | 88.75 | 94.86 | 93.23 | 94.04 |
表4 注意力模块消融实验结果Tab.4 Results of attention module ablation experiments (%) |
| 注意力模块位置 | IoU | Precision | Recall | F1-score |
|---|---|---|---|---|
| ASPP+CAM+SAM | 88.82 | 94.86 | 93.31 | 94.08 |
| ASPP+SAM+CAM | 88.52 | 95.27 | 92.59 | 93.91 |
| SAM+ASPP+CAM | 88.76 | 94.81 | 93.29 | 94.04 |
| SAM+CAM+ASPP | 86.36 | 93.52 | 91.85 | 92.68 |
| Deep+CAM,Low+SAM | 88.86 | 95.05 | 93.18 | 94.10 |
表5 对比实验分割可视化结果Tab.5 Comparative experiment segmentation visualization results |
| 序号 | 真实图像 | U-Net | FCN | Deeplabv3+ | SC-deep |
|---|---|---|---|---|---|
| 1 |  | ||||
| 2 |  | ||||
| 3 |  | ||||
表6 对比实验结果Tab.6 Compare experimental results (%) |
| 模型 | IoU | Precision | Recall | F1-score |
|---|---|---|---|---|
| U-Net | 85.13 | 92.31 | 91.62 | 91.97 |
| FCN | 87.95 | 93.66 | 93.52 | 93.59 |
| Deeplabv3+ | 84.48 | 93.20 | 90.03 | 92.59 |
| CS-deep | 88.86 | 95.05 | 93.18 | 94.10 |
| [1] |
胡明洪, 李佳田, 姚彦吉, 等. 结合多路径的高分辨率遥感影像建筑物提取SER-UNet算法[J]. 测绘学报, 2023, 52(5):808-817.
|
| [2] |
吴炜, 骆剑承, 沈占锋, 等. 光谱和形状特征相结合的高分辨率遥感图像的建筑物提取方法[J]. 武汉大学学报(信息科学版), 2012, 37(7):800-805.
|
| [3] |
贾士军, 王昆. 融合颜色和纹理特征的彩色图像分割[J]. 测绘科学, 2014, 39(12):138-142,147.
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
季顺平, 魏世清. 遥感影像建筑物提取的卷积神经元网络与开源数据集方法[J]. 测绘学报, 2019, 48(4):448-459.
|
| [13] |
|
| [14] |
赵凌虎, 袁希平, 甘淑, 等. 改进Deeplabv3+的高分辨率遥感影像道路提取模型[J]. 自然资源遥感, 2023, 35(1):107-114.doi:10.6046/zrzyyg.2021460.
|
| [15] |
|
| [16] |
|
| [17] |
吕少云, 李佳田, 阿晓荟, 等. Res_ASPP_UNet++:结合分离卷积与空洞金字塔的遥感影像建筑物提取网络[J]. 遥感学报, 2023, 27(2):502-519.
|
| [18] |
|
| [19] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}